واحدة من أعظم مهاراتي وربما موهبتي الوحيدة في وقتٍ مضى كانت أن أوجد العذر المناسب لإرجاء وإخماد الأمور التي يجب القيام بها مثل المذاكرة، ممارسة الرياضة، وغيرها من المهام اليومية التي لابد وأن تجعل من كل فرد شخصاً أفضل. وكان السبب الحقيقي وراء كل تلك الأعذار: أنني ببساطة لا أحب عمل هذه الأشياء ليس إلا
The for loop. It is a cornerstone of programming — a technique you learn as a novice and one that you’ll carry through the rest of your programming journey.
If you’re coming from other popular languages such as PHP or JavaScript, you’re familiar with using a variable to keep track of your current index.
// JavaScript Example
let scores = [54,67,48,99,27];
for(const i=0; i < scores.length; i++) {
console.log(i, scores[i]);
}
/*
0 54
1 67
2 48
3 99
4 27
*/
It’s critical to understand that these for loops do not actually iterate over the array; they manually iterate via an expression that serves as a proxy for referencing each array value.
In the example above, i has no explicit relation to scores, it simply happens to coincide with each necessary index value.
The Old (Bad) Way
The traditional for loop as shown above does not exist in Python. However, if you’re like me, your first instinct is to find a way to recreate what you’re comfortable with.
As a result, you may have discovered the range() function and come up with something like this.
scores = [54,67,48,99,27]
for i in range(len(scores)):
print(i, scores[i])
"""
0 54
1 67
2 48
3 99
4 27
"""
The problem with this for loop is that it isn’t very “Pythonic”. We’re not actually iterating over the list itself, but rather we’re using i as a proxy index.
In fact, even in JavaScript there are methods of directly iterating over arrays (forEach() and for…of).
Using the enumerate() Function
If you want to properly keep track of the “index value” in a Python for loop, the answer is to make use of the enumerate() function, which will “count over” an iterable—yes, you can use it for other data types like strings, tuples, and dictionaries.
The function takes two arguments: the iterable and an optional starting count.
If a starting count is not passed, then it will default to 0. Then, the function will return tuples with each current count and respective value in the iterable.
scores = [54,67,48,99,27]for i, score in enumerate(scores):
print(i, score)
This code is so much cleaner. We avoid dealing with list indices, iterate over the actual values, and explicitly see each value in the for loop’s definition.
Here’s a bonus, have you ever wanted to print a numbered list but had to print i + 1 since the first index is 0? Simply pass the value 1 to enumerate() and watch the magic!
scores = [54,67,48,99,27]
for i, score in enumerate(scores, 1):
print(i, score)
"""
1 54
2 67
3 48
4 99
5 27
"""
I hope this tutorial was helpful. What other uses of the enumerate() function have you found? Do you find the syntax easier to read than range(len())? Share your thoughts and experiences below!
If you’re just starting out in the field of software engineering and have begun applying for junior engineering jobs — you might have run into a brick wall. Every company seems to have loosely defined the responsibilities of the job and no clear expectations have been made.
This is especially tricky since every corporation has its own set of rules and standards for software engineers. Chances are high that you might have read a long list of demands, and you may have begun wondering when exactly is the right time to start applying for jobs as a junior engineer?
This article will open the pandora’s box and explain the what, when, and how. Here’s what a Software-as-a-Service (SaaS) company might expect from you when you’re starting out on your first job as a junior developer.
Since I’m primarily a JavaScript engineer, let’s think about it in JavaScript terms. If you have a good understanding of JavaScript, then you can easily pick up new frameworks. Or, at the very least, you won’t be lost learning them.
If you have a good grasp of a language, then you should be able to learn new concepts specific to the corporation or use specific technologies designed to work with that language.
Most places won’t expect you to be an expert on the language itself unless you market yourself that way. Some interviewers might probe your knowledge pretty intensely, but this is usually just to see what you know.
There’s always room to grow, and the interviewer will push the boundaries to see where you come up short. Don’t be afraid to tell someone you don’t know the answer. This is a technique to see how people handle not-knowing. I’d much rather hire someone who responds with something like, “I don’t know, but here’s what I’d do to figure it out” over someone who tries to cover up their lack of knowledge. Honesty goes a long way.
You Need to Be Able to Build Something and Demonstrate Your Potential
When it comes to becoming employable in the programming field, the most important skill to have is to be able to build something. Programmers are makers, and they produce code and build products. It takes a specific mindset to be able to constantly produce. You need to be OK with being out of your comfort zone, and you have to be ready to learn and eager to push things forward, even when going against the tides of bureaucracy and sometimes incompetent management.
Start building today and don’t waste time — after all, it’s the most precious resource we have. We can always acquire more money and stuff, but we can’t acquire time. It’s a limited resource for everyone.
You can build anything, as long as you’re building. Spin up a PostgreSQL database, fill it with animals, fetch the data, and display it in the browser. If you’re out of ideas on what to build, here are six front end challenges you can start working on today.
I’ve always said the secret to being a really good developer is building things. Compare it to bodybuilding or jogging; you have to actually go to the gym and lift weights every day to achieve results. The same goes for coding. You have to open your code editor and start building things to acquire the knowledge. Don’t spend too much time only reading books. Spend 80% of your time in the code editor.
Consider Most Job ‘Requirements’ as ‘Nice-to-Haves’
Don’t be alarmed when you see a long list of demands on a job post. These are all “nice-to-haves” since the ideal candidate doesn’t exist. Usually, the hiring person has little-to-no clue about technical matters and will regurgitate a bunch of words on a piece of paper. My advice is to research the background and mission of the company. If you believe in what the company is doing and its mission, it’s worth applying to.
For entry-level programmers, there are two types of employers: the problem-solvers and the soon-to-be experts.
The problem-solvers (e.g. Google, Apple, Microsoft) want to hire problem-solvers. The math folks or the algorithm-wizards; people who can invent solutions to new problems. They also expect you to ramp up quickly on new technologies. There’s little hand-holding, and you’ll be expected to be an efficient problem-solver by the second or third month already. People with a solid education in algorithms and exceptional problem-solving intelligence will like these types of companies.
The expert types (e.g. government, app factories, most banks, internal IT departments) want engineers with a depth of experience in specific frameworks or technologies. They operate in a well understood or highly specialized technical domain. Technological innovation doesn’t interest them — they’re looking for rapid execution of well-understood techniques. They’re either happy with the status quo or may drive their business with product-focused innovations. These are also considered a “maintenance” job as you need to keep the wheels running and the system going. These types of jobs are more relaxed jobs with fewer demands, and they usually pay less and are less interesting and less challenging.
Figure out which employment type you’re suited for. If you don’t think you can (or don’t want to) be an exceptional problem-solver, then focus on expert roles. In which case, I would start a spreadsheet with their requirements; count up the most common ones and spend three to six months building and publishing an end-to-end project. Make sure to make it publically available for everyone to see.
When Should I Start Applying for Junior Engineering Jobs?
There’s a proverb that goes like this: “The best time to plant a tree was 20 years ago. The second best time is now.” In the context of applying for jobs, the best time to start applying was already yesterday. You learn the most when you’re working since you’re constantly being barraged with real-world problems.
Spend an hour a day just scanning for jobs, and see what interests you. If you see an interesting job post, research the company, see what they do, who works there, and what kind of technology they use. If you’re really keen on becoming a Googler, learn Go or C++. If you want to work for startups, learn Node and React. Figure out what kind of a job you want and start preparing for the requirements. Nothing good falls into your lap. You have to put in the effort and fight for it.
Nothing good worth doing comes easy — if it was easy, everyone would be doing it. It’s challenging when you’re just starting out, but I guarantee it’s a fun and exciting path to take.
Thanks for reading, stay curious, and keep your head up high as you move forward. Good luck on your adventure!
I recently wrote about “5 Books That Changed the Way I Code.” In the comments, several readers recommended “Clean Code” by Robert C. Martin. As a result, I’ve now read the book and found it worthy of an in-depth review.
About the Book
“Clean Code” was published in 2008, and over recent years, it has consistently ranked as one of the top five highest-selling books on Amazon. The author, affectionately known as “Uncle Bob,” was one of the original authors of the Agile Manifesto and has some serious credentials. The book has achieved an average rating of 4.4 on Goodreads from over 13,000 ratings. Suffice to say, it’s one of those books every programmer should read.
In this review, I’m going to condense the book into five essential takeaways.
The reticulate package allows R and Python to work together — here’s a tutorial
R and Python have many similarities and many differences. Most of the underlying concepts of data structures are very similar between the two languages, and there are many data science packages that now exist in both languages. But R is set up in a way that I would describe as ‘data first, application second’, whereas Python feels more application development driven from the outset. Javascript programmers, for example, would slot into Python a little quicker than they would slot into R, purely from a syntax and environment management point of view.
More and more I have been working in R and Python and I have come across situations where I’d like to use bothtogether. This can happen for numerous reasons, but the most common one is that you are building something in R, and you need functionality that you or someone else has written previously in Python. Sure, you could rewrite it in R, but that’s not very DRY is it?
The reticulate package in R allows you to execute Python code inside an R session. It’s been around for a few years actually, and has been improving more and more, but it’s only recently that I’ve needed to use it, so I wanted to type up a brief tutorial on how it works. It you are an R native, getting reticulate up and running requires you to understand a little about how Python works — and how it typically does environment management — and so this tutorial may help you get it set up much quicker than if you tried to work it out yourself.
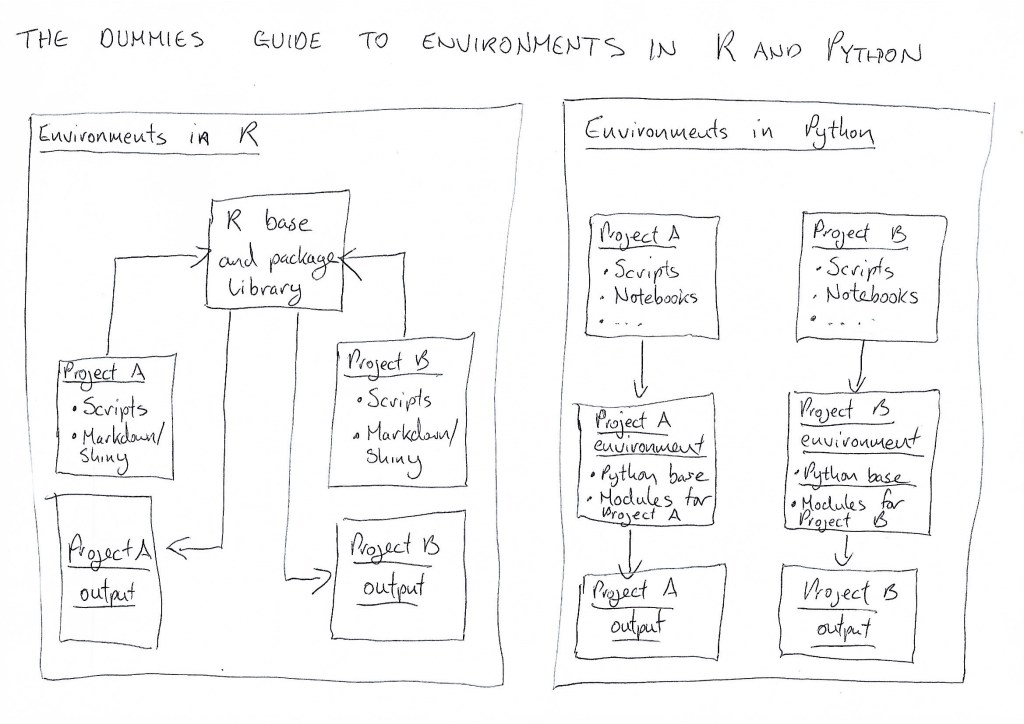
Environments in R and Python
Any programming project operates in an environment, which is where it stores and accesses all the things in needs or creates during its execution. In R, a common global environment is available to all projects, where the R base language and all installed packages are to be accessed. In this sense, all projects in R are usually run through the same common core environment. One way to think about this is to imagine that everyone in your house shares the same charging hub for their iPhones. They have to leave their room to charge the phone, and if they sell it the buyer will need to sort out their own charging arrangement.
In Python, however, each project is usually set up to be completely self contained — with its own environment, its own copy of the Python base and independent copies of all the modules it needs to execute. You can think about this as everyone having their own iPhone charger in their room. They don’t have to go outside and plug in somewhere else, and if they sold the phone, it comes complete with its own charger.
The Python model is more expensive in terms of installation processes and disk/memory resources, but it allows easier transfer of projects between individuals with minimal configuration, so it’s not hard to see how it has grown more directly out of a software development mindset, which is why I regard Python as more ‘application driven’.
Here’s a little graphic I sketched out to explain in simple terms the difference between how environments usually work in R and Python:
Typical environment configurations in R and Python
Now, if you want Python to talk to R, it still needs to find its environment — you can’t tell it to access R’s global environment. That would be like telling an English-speaker to find directions by asking a Chinese-speaker.
So, to get Python working inside your R project, you need two things:
A Python environment set up inside your R project, so Python can get its bearings
The reticulate package to translate the Python code so that it works in R
Setting up a Python environment
From now on I am going to use a simple example. Let’s suppose I have an R project in RStudio which needs to use a function I have written in Python. So here’s a simple function which I will save in a Python script called light_years.py in my R project directory called test_python (yes, RStudio allows you to create Python scripts!). This function takes a distance in either kilometers or miles as an input and calculates how many years it would take to travel that distance at the speed of light — in other words, what is the distance in light years:
from scipy.constants import c
def light_years(dist, unit = "km"):
c_per_year = c * 60 * 60 * 24 * 365.25
if unit == "km":
dist_meters = dist * 1000
elif unit == "mi":
dist_meters = dist * 1.60934 * 1000
else:
sys.exit("Cannot use that unit!")
return dist_meters/c_per_year
I am using a very simple function example here to keep this article straightforward, so it’s a little unrealistic, and also a bit silly since I am importing the entire scipy package just to get the value of a constant, but hopefully it will help you get the idea.
Now as we discussed above, we need to provide this code with an environment. It needs:
A version of Python to work through
Access to the scipy package so it can get the constant c = speed of light
It’s not hard to set up a Python environment for your R project. Given how important project environments are in Python, numerous easy to use environment management tools exist.
My favourite is Anaconda. There are two versions available. The full version, contains a large universe of all the things an environment may need, including all the most used Python modules. Then there is Miniconda, which is easier on disk space and more appropriate for limited Python users. You can get Miniconda for your operating system here. Make sure you are downloading Conda for the version of Python that you want to work in.
Once you’ve installed Conda, if you are in MacOS or Linux, you’ll usually setup your environments using the command line. Just navigate to your R project directory (in my case test_python) in the terminal and use this command:
conda create --name test_python
Simple as that, you now have a python environment created. I usually name my environments the same as the project folder to avoid future confusion.
Now you need to tell Conda to use that environment for this project, so while still in your test_python directory in the command line, use this command:
conda activate test_python
And now you’ve linked this project to the Python environment, and there is a copy of the Python base in there for your code to run through.
Finally, our function needs the scipy package, so we will need to have that inside the environment. This is as simple as typing this inside the activated project folder:
conda install scipy
Conda will then install scipy and all dependencies it thinks it might need into your active environment and you are ready to go — easy as scipy, so to speak.
Now, later you are going to need to tell R where to find Python in this environment, so if you use this command, you can get a list of all environments and the path to where the environments were installed:
conda info --envs
This tells me, for example, that my environment was installed at /Users/keithmcnulty/opt/miniconda3/envs/test_python. I can always find the Python executables inside the bin subdirectory — so the full path to the Python executable for my project is /Users/keithmcnulty/opt/miniconda3/envs/test_python/bin/python3, since I am using Python 3. This is everything we need to tell R where to find the Python environment.
Running your Python function in R
Now, whether you’ve set up your Python environments like I did using Conda, or whether you have used virtualenv, you’ve done the hard bit . The rest is straightforward because reticulate takes care of it.
First, you need to tell R where to find the Python executable in the right environment when it loads your project. To do this, start up an empty text file and add the following, replacing my path to whatever path matches your Python executable inside the project environment you created.
Now save this text file inside your project directory with the name .Renv. This is a hidden file that R will execute whenever you start up your project in RStudio. So now shut down RStudio and restart it with your test_python project open and it will now be pointing to the Python environment.
Now if you haven’t already installed the reticulate R package, you should do so at this point. Once installed, you can try a few tests in the terminal to see if everything is as it should be.
First you can test if R knows where Python is. reticulate::py_available() should return "TRUE". You can also test if the Python modules you need are installed: reticulate::py_module_available("scipy") should return "TRUE". Assuming all that works, you are ready to bring your function into R.
You can source your Python script with a simple:
reticulate::source_python("light_years.py")
Now you have the light_years() function available as an R function. Let’s see how many years it would take to travel a quadrillion miles at the speed of light:
Nice! Obviously this is a very simple example but it does tell you all you need about how to integrate Python code into your R script. You can now imagine how you can bring in all sorts of functionality or packages that are currently Python-only and get them working in R — very exciting. For example, I recently needed to use a new graph community detection algorithm called leidenalg for which an implementation only currently exists in Python, but all my existing project code was in R. So I was able to use reticulate just like I did here to solve this problem.
To learn more about using Anaconda or Miniconda to set up Python environments, the user guide is here. To learn more about the wide variety of functionality available to translate Python to R, there’s a goodreticulate vignette here.
Why writing by hand makes you more creative and productive?
Did you know that Paul Lauterbur’s first concept for the MRI machine was sketched out on a restaurant napkin? Or that J.K. Rowling initially scribbled down the idea of the Hogwarts houses on the back of an air sickness bag? Quentin Tarantino writes all his screenplays longhand, buying a specific notebook and pen at the start of each project, and Tinder CEO Elie Seidman swears by pen and paper.
Does it make a programmer weak for using Google or Stack Overflow when coding?
Actually, the way I host interviews for programmers is giving four different programming assignments in specific tight niches, making sure it’s so specific they are unlikely to have any prior knowledge.
They have laptop and access to the internet so they can use Google or any other source of the information they find suitable. (academic papers, etc…)
I make sure they are provided with food and drink (pizza and a beer being most popular), just to break down the sterile atmosphere.
They have as much time as they want to solve problems (which are not trivial at all). If they want to stay all night, they are welcome.
They are allowed to talk to each other and share opinions, use a whiteboard, etc., etc. Someone wants a quick nap? No problem.
A guided project that helps you dive into creating something cool and learn useful programming concepts by yourself!
Finding ways to apply your knowledge only after the learning process essentially means that the learning happened without much of a sense of destination. All we were trying to do was amass all the knowledge we could in the hope that it’d come of use in some distant, mystical future. Doesn’t that feel like procrastination? I believe in an approach to learning that emphasizes doing projects.
Late last year, I began waking up at 5:30 AM to write for an hour then drive to work. It was the hardest thing I had done in a long time. But I did it. And you know what? I bet you could too. Imagine how much better your day would be if you accomplished your hardest, most important work first thing in the morning. The rest of your day would be a breeze. You could relax in the evening without feeling like a bum or stressing because you let another day slip by without doing what you planned. My story of waking up early consists of a 50/30/10/10 split of determination, preparation, execution, and luck. Let me explain…